
こんにちは、ヒューマンクレストの磯部です。
今回はランダム文字列の衝突確率について考察します。
自動テストを運用する際に、意外に何度も実務で使ったことがあるので書いてみました。
なぜこのテーマか
自動テストのスクリプトを書いている時に、テスト対象の仕様として Uniq制約があったら、みなさんはどう対応されているでしょうか。
たとえば、アカウント名を自由入力で登録できるけれども、アカウント名の重複は許さないというような仕様があったとします。
アカウント登録は回帰テストとして、テスト実行毎に行いたいという想定です。
1つの答えはテスト実行毎にデータベースをクリアすることですが、様々な技術的・政治的事情でそれが出来ないことも多いです。
連番をつけるという手もありますが、自動テストの停止・再実行や、並列実行などの際に、悲しいことが色々起こります。
こういった場合、私はテスト実行毎にランダム文字列を生成して対応することにしています。
衝突とは
さて、ランダム文字列生成は、ランダムなので、たまたま同じ文字列が生成されてしまう確率が0ではありません。
ランダムに生成した文字列同士が一致することを衝突と呼びます。
生成したランダム文字列の衝突が起こると、Uniq制約に引っかかり、自動テストが(テスト対象に問題がないにも関わらず)失敗してしまうことになります。
できるだけ避けたい事態です。
ランダム文字列の桁数や文字種を増やせば、衝突確率が減るのは直感的にお判りかと思います。
数字10種だけよりアルファベット25文字のほうが、4桁よりは8桁のほうが、衝突確率は減りそうですね。
しかし、どれくらいの桁数・文字種を確保しておけば、十分に衝突確率を下げられるのでしょうか。
衝突確率の計算
確率計算の方法については、興味が分かれるかと思いますので、結果だけ記載しておきます。
b:文字種の数、d:桁数、n:試行回数、P:衝突確率とすると、以下になります。
![]()
2進数の場合の、試行回数から衝突確率を近似値で計算したのが以下の表です。
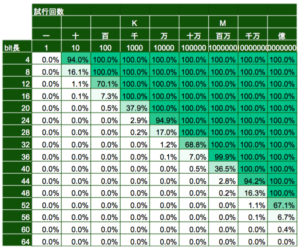
自動テストを想定すると
1年間運用した場合に、衝突確率が 1%以下となる 桁数を計算してみました。
それぞれ、文字種は以下として計算しています。
- 2進数: 0,1 (2種類)
- 数字: 0〜9 (10種類)
- 英数字: 0〜9、A〜Z、a〜z (60種類)
| 実行頻度 | 年間の実行回数 | 2進数 | 数字 | 英数字 |
|---|---|---|---|---|
| 毎日 | 365 | 23桁 | 7桁 | 4桁 |
| 毎時 | 24 x 365 = 8760 | 32桁 | 10桁 | 6桁 |
特に英数字のように文字種が多い場合は、思いのほか少ない桁数で衝突を回避できそうなことが判ります。
ランダム文字列生成の実例
以上の考察から、私は実務でUniq制約に対する対策としてランダム文字列を付加する場合は、英数字 6桁を採用することが多いです。
たとえば、以下のように生成した文字列を、
# ランダム文字列を出力する
def random_string
base= ['0'..'9', 'a'..'z', 'A'..'Z'].map{|b| b.to_a}.flatten
string= (0..5).map{ base[rand(base.length)]}.join
end
自動テストからずいぶん遠いところに来ましたが、いかがでしたでしょうか。
みなさまの業務その他に、ご参考になれば幸いです。